Designing a predictive maintenance solution for IoT
What is predictive maintenance?
Predictive Maintenance is a form of data analysis that uses various IoT devices to assess patterns in machinery that may represent potential problems. Assessing the stages of deteriorating machinery predictive maintenance lets you predict the life cycle of machinery and catch failure before it happens.
Predictive vs preventive maintenance
Predictive maintenance is predicting when a machine will break down and using that information to schedule maintenance in a way that is more efficient for your technician. An example of predictive maintenance is when you use sensor data or engine data to estimate when a machine failure is going to happen.
Preventative maintenance is a maintenance schedule based on a regular and pre-determined cadence - e.g., monthly, annually, or based off of runtime on a machine. An example of preventative maintenance is when you change the oil on your car after ten thousand miles.
Why predictive maintenance is important
Predictive maintenance does is attempt to reduce the frequency of maintenance visits by accurately defining the current state of machinery using various techniques.
IoT for predictive maintenance
By employing IoT devices, predictive maintenance techniques will assess large amounts of data generated by these devices. Then, AI and Machine learning models will churn through the data in order to provide predictions on the state of the machinery. Some of the various IoT devices used for predictive maintenance include, vibration sensors, microphones, thermal sensors, infrared and ultrasonic sensors.
Machine Learning Based Unbalance Detection of a Rotating Shaft Using Vibration Data
This tutorial is adapted from the Machine Learning-Based Unbalance Detection of a Rotating Shaft Using Vibration Data paper submitted by Mey, O.; Neudeck, W.; Schneider, A.; Enge-Rosenblatt, O. to the 25th IEEE International Conference on Emerging Technologies and Factory Automation, ETFA 2020.
We will attempt to detect unbalance on a rotating shaft based on vibration data. We will train and evaluate a fully-connected neural network on data that has undergone a Fast Fourier Transform (FFT) in Collimator.
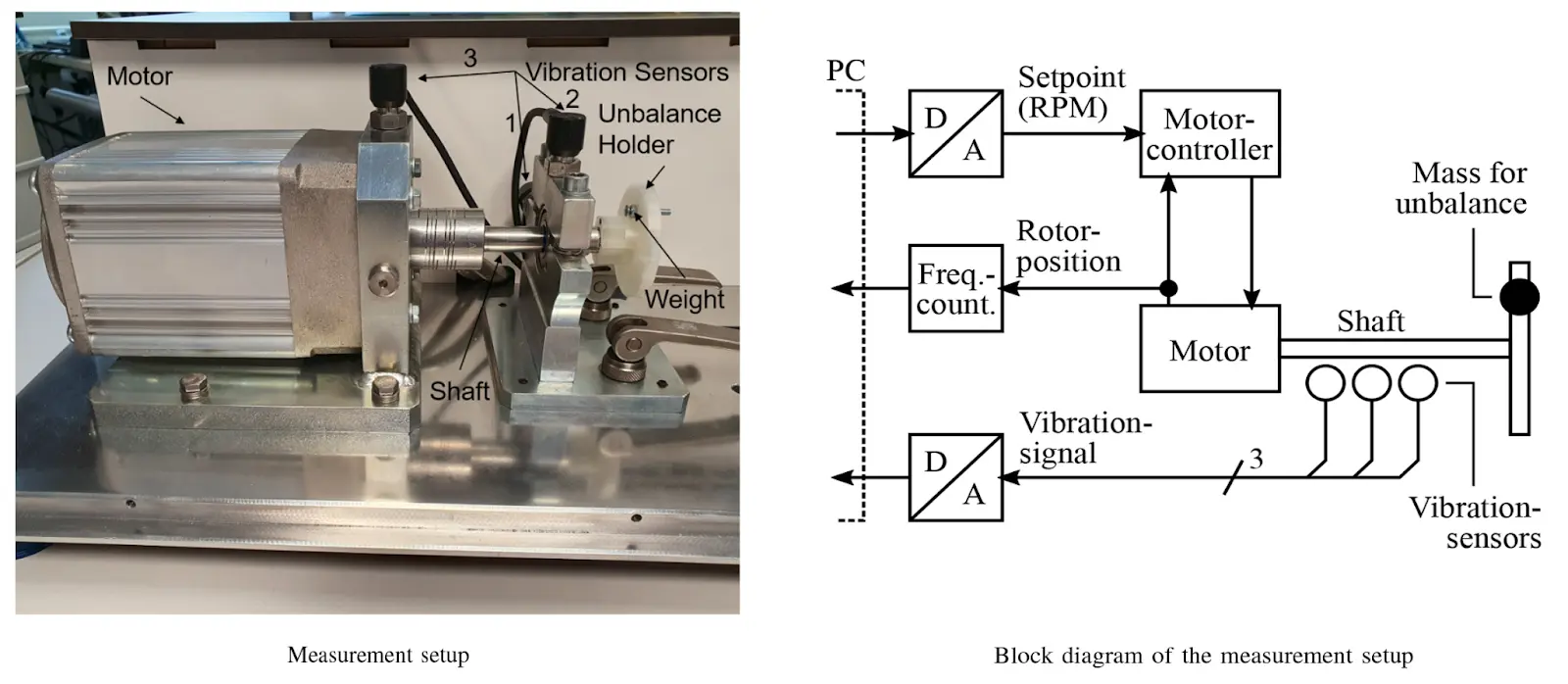
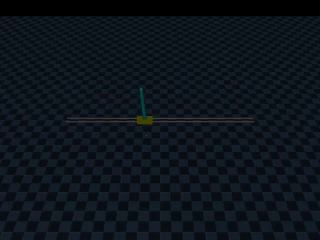
How the data is collected
The setup of the simulation is as follows. A DC motor is controlled by a motor controller which in turn is hooked to a mass of varying sizes. The three vibration sensors are placed in close proximity to the shaft. The model is shown below:
In total, datasets for 4 different unbalance strengths/weights were recorded (1D/1E ... 4D/4E). As well as one dataset with the unbalance holder without additional weight (i.e. without unbalance, 0D/0E). in this case D corresponds with the development or training set and E corresponding with the evaluation set. The unbalance weights are shown in the table below:
We will begin by importing the libraries we will work with:
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
import tensorflow as tf
import zipfile
from sklearn.preprocessing import RobustScaler
After importing our libraries we will unzip the data obtained from the Fraunhofer Fortadis data space:
Next we will assign the CSV files to variables for processing.
with zipfile.ZipFile(url, 'r') as f:
with f.open('0D.csv', 'r') as c:
data0D = pd.read_csv(c)
with f.open('0E.csv', 'r') as c:
data0E = pd.read_csv(c)
with f.open('1D.csv', 'r') as c:
data1D = pd.read_csv(c)
with f.open('1E.csv', 'r') as c:
data1E = pd.read_csv(c)
with f.open('2D.csv', 'r') as c:
data2D = pd.read_csv(c)
with f.open('2E.csv', 'r') as c:
data2E = pd.read_csv(c)
with f.open('3D.csv', 'r') as c:
data3D = pd.read_csv(c)
with f.open('3E.csv', 'r') as c:
data3E = pd.read_csv(c)
with f.open('4D.csv', 'r') as c:
data4D = pd.read_csv(c)
with f.open('4E.csv', 'r') as c:
data4E = pd.read_csv(c)
Next we apply labels and define our samples per seconds and seconds for each analysis. A window of data of which the neural network will make predictions on is defined by the product of the samples per second and the seconds per analysis which are 4096 and 1 respectively.
We create a function to assign the labels to the data for testing. I.e. assigning unbalance (1) vs no unbalance (0) to each data row.
def get_features(data, label):
n = int(np.floor(len(data)/window))
data = data[:int(n)*window]
X = data.values.reshape((n, window))
y = np.ones(n)*labels[label]
return X,y
Next we run through each development data file and each evaluation data file to create two big data files that have the correct unbalance.
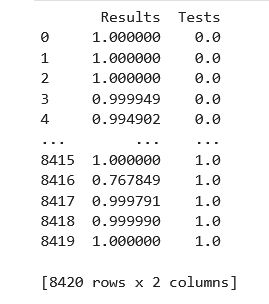
Now the dataset for training X contains 32226 samples with 4096 values each as well as the associated label information y with 32226 labels (one label per sample). The dataset for validating the trained model X_val contains 8420 samples plus the labels y_val accordingly.
print(X.shape, y.shape, X_val.shape, y_val.shape)
(32226, 4096) (32226,) (8420, 4096) (8420,)
Train-Test-Split
Next we will perform a Train test split of the dataset by using Sklearn. The result will be a set for training and a set for testing.
Sklearns Preprocessing library has a Robust Scaler function which works to standardize a dataset by handling outliers properly. Here we eliminate the outliers that are below the 5th quantile and above the 95th quantile range. This helps curb the effect of outliers on skewing the prediction of the neural network.
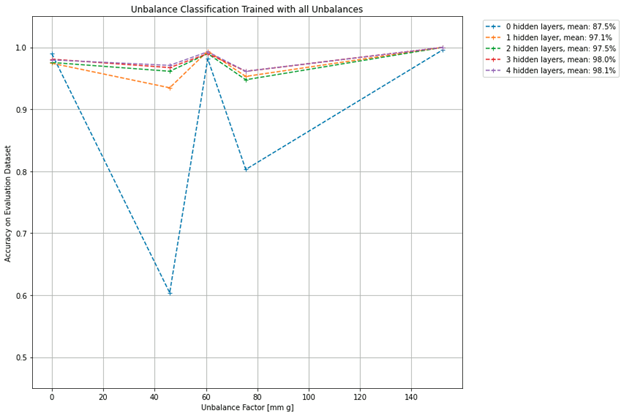
Evaluation of Model performance depending on number of layers
The initial submission of the paper submission to the 25th IEEE International Conference on Emerging Technologies and Factory Automation, ETFA 2020 tested neural networks with hidden layers ranging from zero to four. What it concluded was that the 4th layer neural networks had the most accuracy at 98.1%
Neural network accuracy rate vs number of hidden layers
We're now going to train and test and evaluate a 4 layer fully connected neural network on Collimator. We'll begin by defining our Tensorflow neural network, run at 100 epochs and using 4 hidden layers. Then we will use the Tensorflow's fit function to train and validate our model.
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.layers import BatchNormalization,LeakyReLU,Dense,Dropout
from tensorflow.keras.layers import Input,Conv1D,MaxPooling1D,Flatten,ReLU
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.regularizers import l1_l2
weight_for_0 = len(y)/(2*len(y[y==0]))
weight_for_1 = len(y)/(2*len(y[y==1]))
class_weight = {0: weight_for_0, 1: weight_for_1}
epochs = 100
X_in = Input(shape=(X_train_fft.shape[1],), name="cam_layer")
x = X_in
#the 4 hidden layers
for j in range(5):
x = Dense(units = 1024, activation="linear")(x)
x = LeakyReLU(alpha=0.05)(x)
X_out = Dense(units = 1, activation = 'sigmoid')(x)
model_i = Model(X_in, X_out)
best_model_filepath = f"{model_path}/fft_fcn_5_layers.h5"
checkpoint = ModelCheckpoint(best_model_filepath, monitor='val_loss',
verbose=1, save_best_only=True, mode='min')
model_i.compile(optimizer = Adam(learning_rate=0.0005), loss = 'binary_crossentropy',
metrics = ['accuracy'])
model_i.summary()
At this point we can see that our model has a predictive accuracy of 99% on the training set. The next step will be to run the model against our evaluation data and see how it fairs.
Our model has an accuracy of 97% on data the evaluation data. We can then compare the neural networks guesses with the actual guesses and pinpoint windows that the next struggled with for future testing.






.png)